
By Joël Kuiper
Senior Data Scientist, Doctor Evidence
Introduction
There is no shortage of data in the field of medicine. The rate of publication in medical literature is increasing exponentially. Genetic sequencing, medical imaging, and ever more detailed Electronic Medical Records provide a staggering amount of data. While this can undoubtedly lead to new insights, the flip side is that all this data puts a huge strain on researchers, institutions, and health practitioners. Computers have created an interesting situation: there is now access to so much data, that nobody really knows how best to make use of this potential resource.
While the amount of data keeps growing, so does the cost of health care. It has sometimes been called “Eroom's law”, Moore’s law spelled backwards. Where Moore’s law states that integrated circuits will double the number of transistors every two years, Eroom’s law states that the cost of developing a new drug doubles every nine years.
The reason for this is (as always) complicated, but our limited ability to derive actionable insights from data likely plays a critical role.
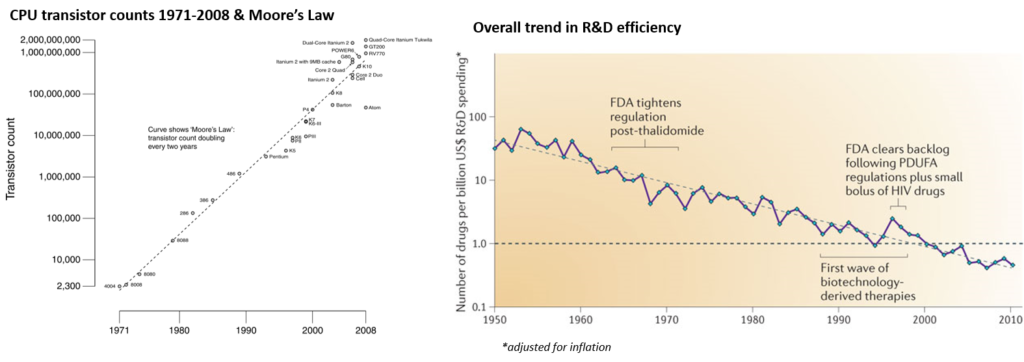
Moore’s Law shows CPU transistors increasing over time, while Eroom’s Law suggests drug discovery does not keep pace with this advancing technology, both slowing down and becoming more expensive as time progresses.1,2
In the words of Vannevar Bush in his seminal piece “As We May Think” 3: “The investigator is staggered by the findings and conclusions of thousands of other workers–conclusions which he cannot find time to grasp, much less to remember, as they appear”. Where Vannevar Bush envisioned a precursor to what we now know as the “World Wide Web” to solve this problem, the reality is somewhat ironic. It has sometimes been called “the paradox of automation:” while we are more effective than ever at automation, the truth is that we are working harder and longer; instead of shorter and better.
Artificial Intelligence in medicine
With the ability to perform staggering amounts of computations per second, the advent of computers in the 1970s promised to solve much of the outstanding problems in medicine: from diagnosis to drug discovery, patient care to logistics. Everything seemed possible in this golden age of computing. Unfortunately, the complexity of medicine was greatly underestimated.
Take MYCIN (~1970) for example. MYCIN attempted to solve the diagnosis and treatment of bacterial infections by applying decision rules and Bayesian statistics.4 The program worked by asking a series of yes/no questions, which gave the system enough information to yield a decision. It performed on-par with human experts, but it was never used in practice.
Many expert systems like MYCIN were developed. But they were over-hyped, and all eventually under-delivered. This fuelled a general feeling of distrust towards Artificial Intelligence (AI), eventually sparking an “AI winter.” A period in which relatively few new developments ensued due to lack of funding, caused by disappointment from expensive and under-performing systems.
Today, we seem to be in a new renaissance. Terms like “Deep Learning,” “Cognitive Computing,” and “Artificial Intelligence” dominate the media landscape. But to avoid the pitfalls of the past, one must be acutely aware of the history of Artificial Intelligence.
Here to Help5

Challenges
The truth is: there is no panacea in AI. Everything is a trade-off, and everything is more complicated than it seems. Take natural language processing for example. From the perspective of a computer, there are only bits and bytes: letters without meaning. And working with medical language inevitably raises the question “what is intelligence?” What does it really mean to understand language, a question, or evaluate the truth of an answer? Intuitively, we may think that “search” or “logic inference on massive graph databases” can’t be it. The philosopher John Searl attempted to grasp this intuition in his Chinese room thought experiment. It goes roughly like this. Picture a person growing up in a box, with no contact with the outside world. Inside the box there is a huge rule book with two columns: one with Chinese characters, the other with English words. The box has one entry point. Whenever somebody slips a piece of paper with a Chinese character through it the person looks it up in the rule book, writes down the English translation from the other column, and slips it back. The question is: does the person inside the box understand Chinese? Does the box understand Chinese? If the answer is “no” to these questions, it must be true that a computer cannot understand language either -- or so the thought experiment goes.
Questions like this may only seem interesting with a good glass of wine, but when building AI for medicine it is a reality you are confronted with daily.
Looking forward
There are certainly success stories in narrow domains, but applying the blanket concept “let’s solve it with AI” will likely lead to disappointment. This is not meant as a discouragement, as the field is still evolving rapidly. Every day we progress in our understanding of intelligence, computer science, and informatics. This highlights an important theme in Artificial Intelligence: we perceive everything that has already been done as not-AI. It’s called “AI of the gaps” -- only those things that currently cannot be done with computers can be AI, the rest simply isn’t. Not long ago playing Chess or Go, or driving a car, were pinnacles of human intelligence; the fact that computers can now do these things better than most humans makes them an improper test for intelligence. Thus, we keep moving the target. There’s always a next thing, and that makes applying AI to medicine so exciting.
AI has a rich history of failure and success, but it has always been a collaboration between our biological minds and those of silicon. It is a journey we travel together with the computers.
References:
- Wgsimon. Transistor counts for integrated circuits plotted against their dates of introduction. The curve shows Moore's law - the doubling of transistor counts every two years [Image]. Retrieved May 8, 2017
- Scannell JW, Blanckley A, Boldon H, et al. Diagnosing the decline in pharmaceutical R&D efficiency. Nat Rev Drug Discov. 2012;11;191-200 .
- Bush V. As We May Think. Atl Mon. 1945;176(1):101-108.
- Shortliffe EH. Computer-Based Medical Consultations: MYCIN. Elsevier/North Holland, New York, 1976.
- Here to help [Cartoon]. Retrieved May 4, 2017.
![Wgsimon. Transistor counts for integrated circuits plotted against their dates of introduction. The curve shows Moore's law - the doubling of transistor counts every two years [Image]](https://en.wikipedia.org/wiki/File:Transistor_Count_and_Moore%27s_Law_-_2008.svg){kind=link}
About the author:
Joël Kuiper had once set out on doing academic research for a living, but then thought better of it. He has a Bachelor of Science degree in Artificial Intelligence from the University of Groningen, the Netherlands. He dropped out of a PhD program in genetics and epidemiology, and is currently trying to push state-of-the-art machine learning and natural language processing for bio-medicine.