Featured Commentary:

By Eric Topol, MD
Executive Vice President, Scripps Research
Founder and Director, Scripps Research Translational Institute
Professor, Molecular Medicine
Introduction
If we are ever going to breakout from our United States healthcare economic crisis, the two biggest line items—human resources and hospitals— of our $3.5 trillion per year expenditures will need to be squarely addressed. In late 2017, the United States economy made healthcare jobs number one, towering well over retail for the first time, and this sector continues to account for the largest proportion of employment growth. Of all healthcare jobs, 1 of every 3 are for staffing the >6000 hospitals, and, cumulatively, hospitals, at well over $1 trillion, are nearly one-third of the healthcare annual expenses. Yet the major outcomes for the US are poor: the only country in the developed world with decreasing life expectancy three years in a row (see Figure 1), along with the worst maternal, infant, and childhood mortality of all the 36 Organisation for Economic Co-operation and Development (OECD) countries. These key metrics are indeed surprising given that we spend over $11,000 per person per year, representing a distinct outlier that is 2 to 3-fold the other OECD countries. Clearly, we have a broken, paradoxical model of unbridled investment in human capital with worse human health outcomes.
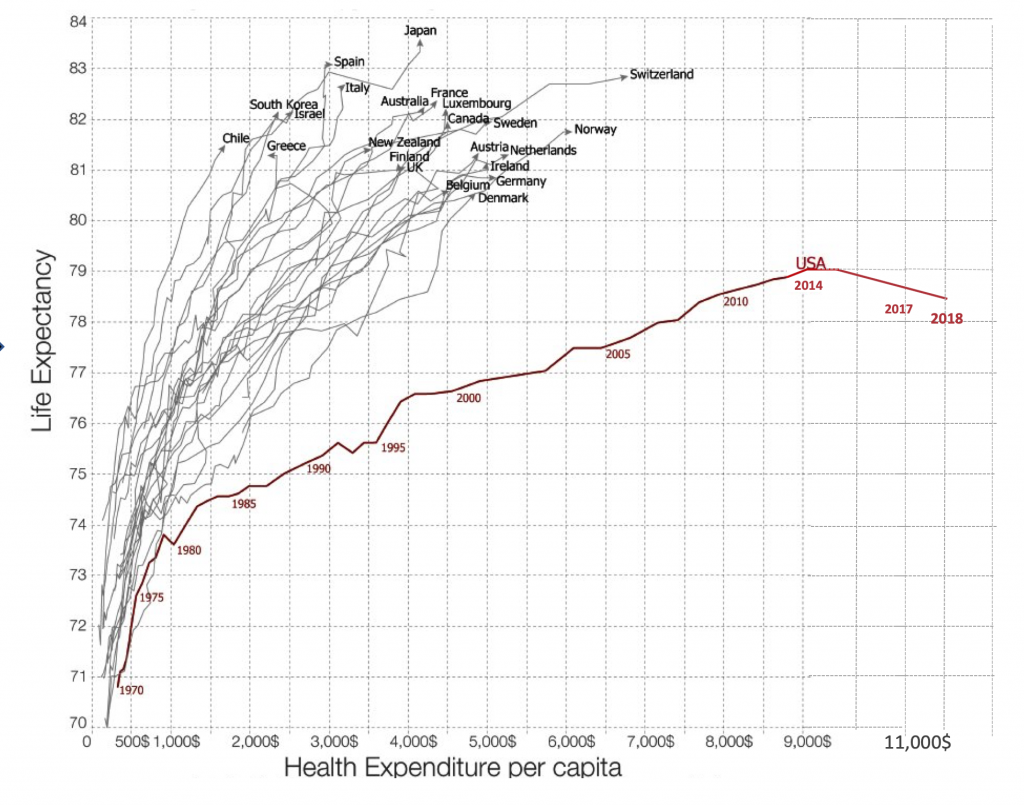
Figure 1. Life Expectancy in US vs Other Countries and Cost of Healthcare per Capita
Helping Doctors
The last decade has ushered in deep neural networks, a new subtype of artificial intelligence (AI). With that is a new capability to input medical images, speech, and text through layers of artificial neurons and rapidly obtaining accurate output identification and classification, at levels comparable or even exceeding expert doctors. The interpretation of medical scans, pathology slides, skin lesions, and machine vision diagnosis of colon polyps underscore a new reality: we can train machines to see things that humans cannot. Other forms of artificial intelligence, including machine learning and natural language processing, show promise for doctors to be liberated from keyboards. In the recent United Kingdom’s National Health Service review of technology to plan its future workforce, economic modeling showed that for every 1 minute using speech instead of keyboard typing equated to 400,000 hours of clinical encounter time or the full-time work of 230 doctors. Currently, there are over 60,000 human scribes that are working in the United States to free up doctors from data clerk functions, and that number is projected to reach 100,000 by the end of next year. We are at peak levels of physician burnout and depression, and know that for doctors who suffer burnout there is a doubling of medical errors.
Augmenting doctor’s performance with machine algorithms has the potential to reduce burnout, reduce medical errors, and markedly improve productivity. In the field of radiology, for example, there is over a 30% false negative rate for the interpretation of medical scans, which can be substantially reduced by algorithmic screening before the radiologist’s interpretation. We’ve already seen FDA approvals of deep learning AI to diagnose diabetic retinopathy, abnormal heart rhythm, or a urinary tract infection without a doctor. As more of these self-diagnoses are validated and enable patients to take charge, obviating the need to rely on doctors for common conditions, the current clinician workload will be further decompressed. Beyond the ability to lessen the requirement for doctors and health professionals, AI algorithms can be built to decrease back-office personnel engaged in such health systems and clinic operations as billing, coding, and administrative tasks. The common thread of outsourcing many functions and jobs to machines represents one attractive solution.
Reducing Costs
Yet there is another major factor that accounts for our runaway healthcare costs that may be ameliorated by AI—-the waste and unnecessary procedures and testing which are estimated to be 34 per cent of expenditures. Some of the waste can be attributed to lack of physician time with patients, with reflexive ordering of tests and unwarranted prescriptions. Mass screening of the population irrespective of individual risk, with mammography, prostate-specific antigen (PSA), and colonoscopy, also contributes. Now there are polygenic risk scores, which, integrated with traditional clinical risk factors, can help guide whether and how often such testing should be performed. Using AI to cull together and process all of the layers of data for each patient, including electronic records, scans, laboratory tests, sensor and genomic data, or what is known as “deep phenotyping,” may promote more efficient, individualized resource use. Over fifty medical societies have now identified hundreds of procedures and tests that are unnecessary, provide low value for patients, and often engender false positive, incidental findings. But little has been done to change medical practice. Automated alerts to both patients and doctors with links to the evidence might foster undoing and help reign in needless consumption.
The most far-reaching AI strategy for healthcare is to eliminate hospital rooms, shifting non-intensive care to the patient’s home. The cost of a day in a regular hospital room in a non-profit facility averages $2,500 in the United States, and the average stay is 5 days. With wearable sensors that track continuous vital signs, including blood pressure, heart rate and rhythm, blood oxygen saturation, breathing rate, and body temperature, the equivalent of intensive care monitoring can be achieved in a patient’s bedroom. Such remote monitoring can also include sensors and machine vision to detect risk of falling or other instability. With these data inputs, deep neural nets could be built to accurately predict a patient’s risk of decompensation before it occurred, with backup clinical personnel surveillance to intervene as needed. Ultimately, it is possible that a substantial part of hospital facilities as they exist today would be gutted, along with much of the healthcare personnel that staff these facilities. The cost of supplying patients the hardware, algorithms, and broadband Internet connectivity, particularly for those without insurance or for whom it is unaffordable, might be a fraction of the cost of a single hospital day. At the same time, the harm of hospital-acquired infections and the high frequency of medical errors that cumulatively affect one of four hospitalized patients could be avoided.
Rescuing Healthcare
This commentary has laid out blueprints for how AI can play a major role in not only reducing the cost of healthcare but also improving patient outcomes. In order for much of this to be achieved, there will need to be a deep commitment to building annotated datasets at scale, algorithmic development with extensive validation, and rigorous clinical research to provide the unequivocal evidence for patient benefit and safety. Unlike the United Kingdom which has developed a strategy for using AI in healthcare, or China, which is already implementing many of the components reviewed here, the United States has no national strategy and has not provided any new, dedicated financial resources to invest in AI. All we have is an executive order for “maintaining leadership.” That is not commensurate with the remarkable opportunity for facilitating a rescue mission.
About the author:
Eric Topol MD is a cardiologist, professor of molecular medicine, and Executive Vice-President at Scripps Research in La Jolla, California. He is the author of the recently published book Deep Medicine: How Artificial Intelligence Can Make Healthcare Human Again (Basic Books, 2019).
Can AI Help Rescue the Healthcare Economic Crisis?