Assessing the Evidence Series

By Eddy Lang, MD
Introduction
…observational studies can play an essential role in shaping medical care, even when RCTs exist for a given clinical question.
Cast in a negative light
One of the most highly cited examples of how observational studies have steered us wrong involve the use of estrogen replacement therapy. As suggested from observational research like the Nurses’ Health Study, estrogen replacement therapy was long touted as beneficial to the health of post-menopausal women. This research was subsequently de-bunked when the Women’s Health Initiative, an RCT, demonstrated a clear harm signal. The discordance has been widely debated, but is presumably related to uncontrolled confounding in the observational bodies of research, a bias that was perpetuated through a number of projects. In the estrogen replacement example, it is now generally accepted that the benefits seen in the observational studies were in fact the result of healthy behaviors (e.g. exercise and medical follow-up) in women using estrogen for which the studies did not adjust, and not the estrogen itself. In general, however, it is worth noting that there is a strong correlation between the findings of observational studies and those of RCTs.1 The problem, one might imagine, is that in the absence of RCTs, it is uncertain if observational studies for a given question are in fact reliable without the comparison.
As a result of the concerns noted above, observational studies may have received something of a bum rap as the science of guideline development has evolved over the last several years. Within GRADE, observational studies start at a low level of confidence for reported estimates of effect and frequently get knocked down to the very low category when methodological limitations are explored. Only large effect sizes, a dose-response relationship, or most importantly confounding influences detract from the observed effect. This is a relatively rare occurrence in healthcare and as a result, in the absence of RCTs, many guideline panels feel frustrated with GRADE. The framework seems to prevent them from issuing any strong recommendations if they lack a robust body of RCTs in the topic area.
Comparison to RCTs
One important distinction to consider is this: observational studies are sometimes considered synonymous with non-RCTs, although there are experimental designs other than RCTs which can be invaluable for systematic review and guideline development. These include carefully controlled pre-post studies and interrupted time series analyses as well. Similarly, diagnostic accuracy studies are not RCTs and provide a primary assessment of test performance characteristics. Increasingly, systematic reviews and guidelines are tackling prognosis questions and in these circumstances, the tightly controlled and highly patient-selected environment of an RCT may provide a biased perspective. At the end of the day, with the possible exception of focused therapy questions blessed with a robust RCT literature to inform them, observational studies can offer important information for systematic reviewers and guideline developers highlighting real-world issues of compliance, generalizability, and in the case of large studies, adverse events which may not be revealed in RCTs.
Assessment
It is essential to consider our level of confidence in the findings from observational studies that will be incorporated into systematic reviews or will form the basis of a clinical practice guideline. Health record reviews are often plagued with a retrospective design and a reliance on administrative data to define populations and outcomes; thus evaluating the integrity of outcome data across observational studies is necessary in order to identify sources of error and bias in this research. Some might consider the state of the art in this endeavor to be the Newcastle-Ottawa Scale.2 Widely used in systematic reviews, this framework of 8 questions explores risk of bias in regards to three domains – selection, comparability, and outcomes:
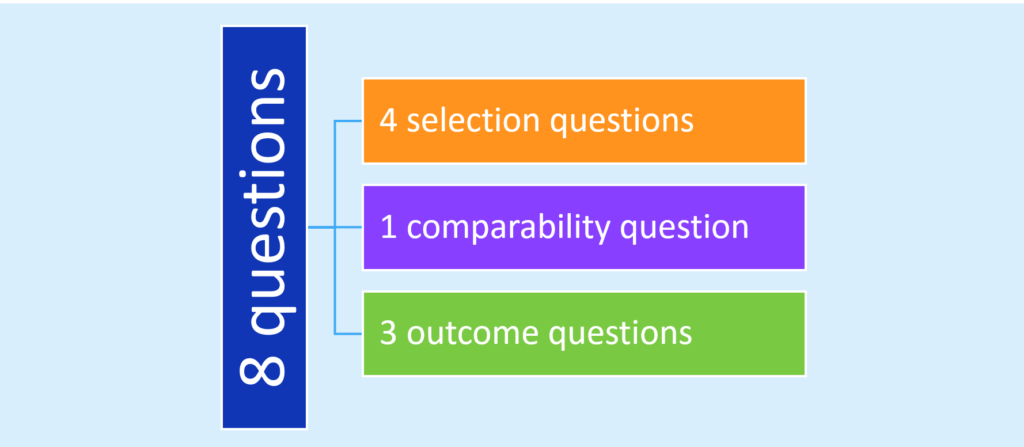
Somewhat arduous to administer, studies have identified limitations in its reproducibility and the requirement to seek out data not generally reported in the published manuscript.3,4
Within the GRADE system, guideline developers are faced with some fairly straightforward questions as it relates to judging risk of bias in observational studies. Assuming an absence of the criteria that led to an upgrade, a methodology team is faced with the decision of whether to maintain a body of evidence pertaining to a specific outcome as low or whether to downgrade further to very low. In that regard, the guideline panels I have worked with tend to prefer the simple 4-item approach encouraged by GRADE and accessible through the online handbook (Table 1). In my experience, failure to adequately control confounding is the most common issue identified in observational studies and thus contributes to a downgrade.

Conclusion
Whichever approach you may choose to adopt for your foray into systematic reviews and guidelines, and you’ll have to use one, it is worth noting that in healthcare as in life, we process many inputs when it comes to making recommendations and clinical decisions. Observational studies can be invaluable sources of insight with regards to healthcare questions, provide complementary knowledge to RCTs, and can at times even suggest best care when RCTs are limited or lacking.
References
- Ioannidis JPA, Haidich AB, Pappa M, Pantazis N, Kokori SI, Tektonidou MG, Contopoulos-Ioannidis DG, Lau J. Comparison of Evidence of Treatment Effects in Randomized and Nonrandomized Studies. JAMA. 2001;286(7):821-830.
- Wells GA, Shea B, O’Connell D, Peterson J, Welch V, Losos M, Tugwell P. The Newcastle-Ottawa Scale (NOS) for assessing the quality of nonrandomised studies in meta-analyses. Accessed July 14, 2016.
- Hartling L, Milne A, Hamm MP, Vandermeer B, Ansari M, Tsertsvadze A, Dryden DM. Testing the Newcastle Ottawa Scale showed low reliability between individual reviewers. J Clin Epidemiol. 2013;66(9):982-93.
- Lo CK, Mertz D, Loeb M. Newcastle-Ottawa Scale: comparing reviewers' to authors' assessments. BMC Med Res Methodol. 2014;14:45.
- Schünemann H, Brożek J, Guyatt G, Oxman A (editors). GRADE Handbook: Handbook for grading the quality of evidence and the strength of recommendations using the GRADE approach [Updated October 2013]. Available at http://gdt.guidelinedevelopment.org/app/handbook/handbook.html. Accessed July 14, 2016.
About the author:
Eddy Lang is the Academic and Clinical Department Head and a Professor of the Department of Emergency Medicine, at the Cumming School of Medicine, University of Calgary. He also holds the position of Senior Researcher with Alberta Health Services. He co-chaired the 2007 Academic Emergency Medicine Consensus Conference on Knowledge Translation which remains an ongoing interest. Dr. Lang is a member of the GRADE working group and has led the development of GRADE-based clinical practice guidelines in pre-hospital care in the US and is currently engaged in the same activity with the International Liaison Committee on Resuscitation. Dr. Lang is also an award-winning educator having received recognition at both the university, national and international levels. He also serves as Senior Associate Editor for the Canadian Journal of Emergency Medicine and Associate Editor for ACP Journal Club and the International Journal of Emergency Medicine. He also writes a quarterly column for the Calgary Herald on Evidence-Based Medicine.